今回は
Jetson nano にインストールしたOpenFrameworks から、OpecCV とDarknet(YOLO) を動かす方法を書きます。
Jetson nano でAI系のソフトをインストールして動かしてみたけれど、これを利用して自分の目標とする「何か」を作るとき、その先膨大な解説と格闘しなければならず、大概行き詰まってしまいます。また、nanoはPI3に比べれば早いといってもIntel の汎用CPUに比べると1/4位のスピード。AIエンジンを利用して応用ソフトを組む場合、インタープリタ型言語であるPython等を使うと、応用部分であきらかに遅くなってしまう傾向がある点は否めません。CythonやSWIGを使えば早くなりますが、結局C言語に戻ってしまうことになります。やはり最初からCやC++等を使って、なるべくCPU処理部分のスピードを上げるのがnanoでは得策と思われます。AIの研究者でもないので基本的な構造学習作業をワープして、即応用に繋がる方法はないものなのでしょうか?。今回は一例としてOpenframeworksとDarknet(yolo)を使って、簡単に応用ソフトを作るためのきっかけがつかめたら良いと考えて記事を書きます。
VIDEO
今回作成したYOLOv2-tinyの動画です。
VIDEO YOLOv2の動画。認識スピードは遅いものの結構正確でした。認識部分を別スレッドで動かしているので、動画に後から追いつく感じ...
なぜOFとDarknet(YOLO)を結びつけるのか?
C++はコンパイラ型言語ですから、できあがったアプリの全体スピードが速いことは常識です。ところがプログラム自体も、コンパイル作業も、一般的に非常に煩雑で、専門外の人間にはに取り付き難いことが欠点でもあります。これらの欠点を大きく改善したものがOF(OpenframeWorks) だと私は認識しています。
OF の優れている点は、オープンソースであることと、文法構成の工夫で初級段階でも高度なグラフィックソフトが出来てしまうこと。さらに先人の作った様々な画像系・サウンド系・その他のライブラリがAdoon という形で簡単に利用できることです。様々なディバイスでアプリが作れますが、私の経験ではMacのXcode環境よりLinuxの方が構造が簡単でプログラムし易いように思います。初心者にとってはコンパイルが時として上手くいかなかったりすることがありますが、日本では2人の先生が初歩から応用までわかりやすく解説していますので参考にしてください。
前橋工科大学 田所先生
yoppa org – 第2回 : クリエイティブコーディング基本 – openFrameworks 1
東北大学 小嶋先生 こじ研(openFrameworks)
YOLO はC言語 を使って開発されていますから、OF を使ってYOLO が簡単に使えたら、どんなこともできそうな気がします。nanoでAI応用プログラムを作ってとても感無量ってことを前回の記事で書きました。
SWAPを作成する
以降のコンパイル作業時にメモリが不足して、止まってしまう可能性がありますので、SWIPファイルを最初に作成するのがベターです。nanoでの設定方法は、Jetsonの世界では有名な方(私はサメのおじさんと呼んでます)以下で説明しています。
Jetson Nano - Use More Memory! - JetsonHacks
nanoにOFをインストールする
前回の記事でも少しヒントを書いたのですが、以前私が書いた記事を参考にして、nanoへのインストール手順をまとめた方がいます。
openframeworks jetson nano instructions · GitHub
実はこの部分の説明をどうしたものか迷っていたので大変助かりました。
この記事はOFのコンパイル環境を作る説明だけなので、さらに手順が必要です。 以降はOFのディレクトリに入りINSTALL.mdを確認して下さい。前回実行したサンプルを含めてOFのexampleが殆どすべて実行できます。サンプルの内容はmigizo さんが紹介しています。nanoはGPU(OpenGL)の性能がなかなかなので、最新のMac Book Proと比較しても遜色ないスピードで動きます。
openFrameworks(v0.9.8)Examples一覧 - Qiita
OFでOpenCVを使う
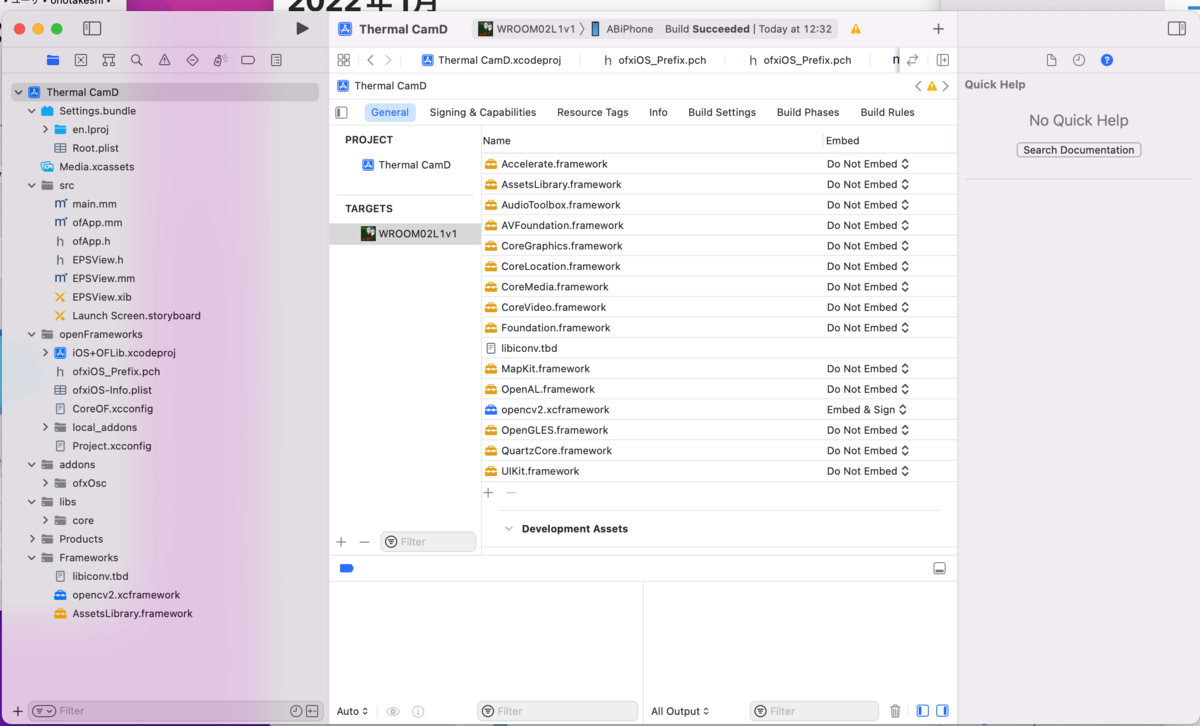
YOLO を使うためにはOpenCV ライブラリが必要です。機能や性能が限られます(contribやGPUが使えない)が、OFにはofxOpenCv とofxCv という有名なaddon があります。ただしこれらのaddonを使わなくともnanoに元々インストールされているOpenCVライブラリや、最新のOpenCVがOFから簡単に導入できます。nanoに入っているのはバージョン3.3ですが、それ以降のOpenCVを使う場合は別途インストールが必要です。
LinuxでOFアプリを作る場合は、myAppsディレクトリの中のemptyExampleをコピーして作って行くことになります。以下の作業でOFからOpenCVが使えるようになります。
1.コピーしたemptyExampleディレクトリの名称を変える。
ディレクトリ名が最終的なアプリ名称になります
中に入っているconfig.makeに次の2行を入れます(79行目と107行目を修正)
PROJECT_LDFLAGS=-DOPENCV `pkg-config --libs opencv`
PROJECT_CFLAGS = -DOPENCV `pkg-config --cflags opencv`
2.ヘッダーファイルを指定する
src/ofApp.h を開き #include "ofMain.h" の後に
#include "opencv2/core/utility.hpp"
等、OpenCVに必要なヘッダーファイルを追加します。後はofApp.cppのsetup()、update()、draw()にOpenCVの様々な関数を書いて実行することができます。さらにusiing namespace cv; を宣言すればもっと使いやすくなります。
反則ですが慣れて来れば、ofApp.cppの先頭に書き込んでもOKです。ofApp.cppに自分で用意した関数を使う場合はそちらの方が簡単かもしれません(今回はofApp.cppにヘッダー宣言を入れています)
3.OFとOpenCVの画像データの受け渡し
一番問題になるのはこの辺りで、OFとOpenCVでは画像データの構造が違うので、変換処理が必要です。この部分を簡単にしたのがofxCVアドオンですが、今回はこのアドオンを使用しない(使えない)ので、基本は次の様な感じで変換します。
OF image形式からOpenCV mat形式 に変換
cv::Mat mat;
ofImage img;
mat=cv::Mat(img.getHeight(),img.getWidth(),CV_8UC3,img.getPixels().getData());
※ CV_8UC3の部分はOpenCVの使用する関数によって変更する必要あり
OpenCV mat形式からOF image形式 に変換
img.setFromPixels( mat.ptr(),mat.cols, mat.rows, OF_IMAGE_COLOR, false);
この2行の変換処理に関して、全体のスピードには殆ど影響が無いようです。
これさえできれば、最新OpenCVの画像処理をOFから自在に利用できるようになります。
Darknetのインストール
このソフトは全体がC言語で開発されていることと、導入が非常に簡単な点が大きな利点です。Nvidiaではnano用に簡単に導入できるAIエンジン(Tensorflowやtorch)も公開していますが、短縮版です。一般的に著名な標準版のCaffe、Tensorflow、torch等をnanoに移植するには、非常な煩雑なインストール手順と長大なコンパイル時間を否応にも経験しなければなりません。しかも最終的にはGPUメモリ容量の問題でアウト!。その点Darknetは、Makefileを少し修正すればmakeコマンドだけで標準版がインストールできてしまい、コンパイル時間もnanoの場合5〜6分で終わってしまいます。コンパイル後はコマンド一発で動画や静止画の認識テストや学習まで出来て、画像認識性能や認識スピードも現在の最新のモノと遜色ないと言ったらどんな不満が出てくるんでしょうか?しかもnanoのメモリ4GBでギリギリセーフ。
前から紹介してきたDarknetは、16ビット小数点演算指定ができるので、スピードではまさにnano向きなのです。一方NvidiaではJetson infarencceというjetsonシリーズで非常に有効なTensorRTを利用した3種類の画像認識が出来るソースを公開しています。(よく知られているオレンジやバナナの認識....)でも、前から思っていたのですがWebカメラを使って実行したところ、さほど認識スピードが速くないのです。特にSegNetは顕著。これはTX1,TX2,Xavierでも同じ印象を受けます。また自分で作ったデータを学習させる場合もDIGITSを使った場合、DIGITS本体のインストール作業や実行上の独特の手順が要求されます。でも最終的に出来たモノはスピードや認識精度共YOLOと互角又は性能が落ちる様に思えます。みなさんも是非試してみることをおすすめます。ある意味これがメーカー水準と言うことになることになると思います。
ではYOLOは完全にnano向きかといえばそうでもありません。今回のDarknetは過去のバージョン(V2)も試せますが、標準データではやはり遅くなるので、アプリを作るのであればTiny yolo v3やTiny yolo v2を使うことになると思います。認識結果もさほど悪く無いことが分かっています。インストールは前回の記事を参考にしてください。
Jetson Nano を使ってみる!! - Take’s diary
今回はMakefileのLIBSO=1
ジャーこれを使ってOFでプログラムを書くには
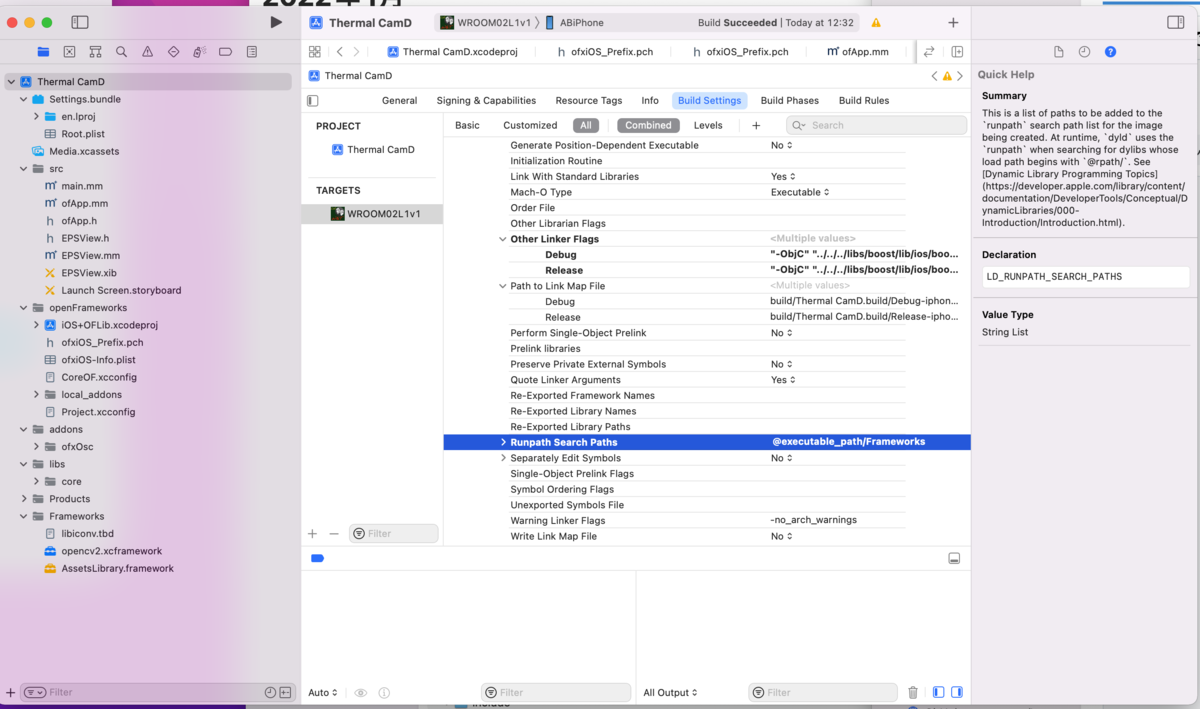
どうすればいいんでしょうか?Darknetは頻繁に修正を行っているので、いつも最新版を利用したいのですが、addonにするとそういうわけにはいかなくなります。そこでDarknetのsoファイル(Shared Objectファイル)を直接リンクすることにしました。
以下の様にします。
Darknetフォルダが ~/darknet であることを想定しています
1.config.makeに次の2行を入れます(79行目と107行目を修正)
PROJECT_LDFLAGS=-DOPENCV `pkg-config --libs opencv` -lm -pthread -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand -lstdc++ -L ./ ~/darknet/libdarknet.so
PROJECT_CFLAGS = -DOPENCV `pkg-config --cflags opencv` -DGPU -I/usr/local/cuda/include/ -DCUDNN -DCUDNN_HALF -Wall -Wfatal-errors -Wno-unused-result -Wno-unknown-pragmas -DGPU -DCUDNN_HALF
2. OFのプロジェクトフォルダにリンクファイルを作る
プロジェクトフォルダ/src の中に以下の様にsrc1という名称のリンクフォルダを作成します。リンク先はdarknet/src です。
srcフォルダの中でターミナルを起動して、以下のコマンドを実行します
ln -s ~/darknet/src ./src1
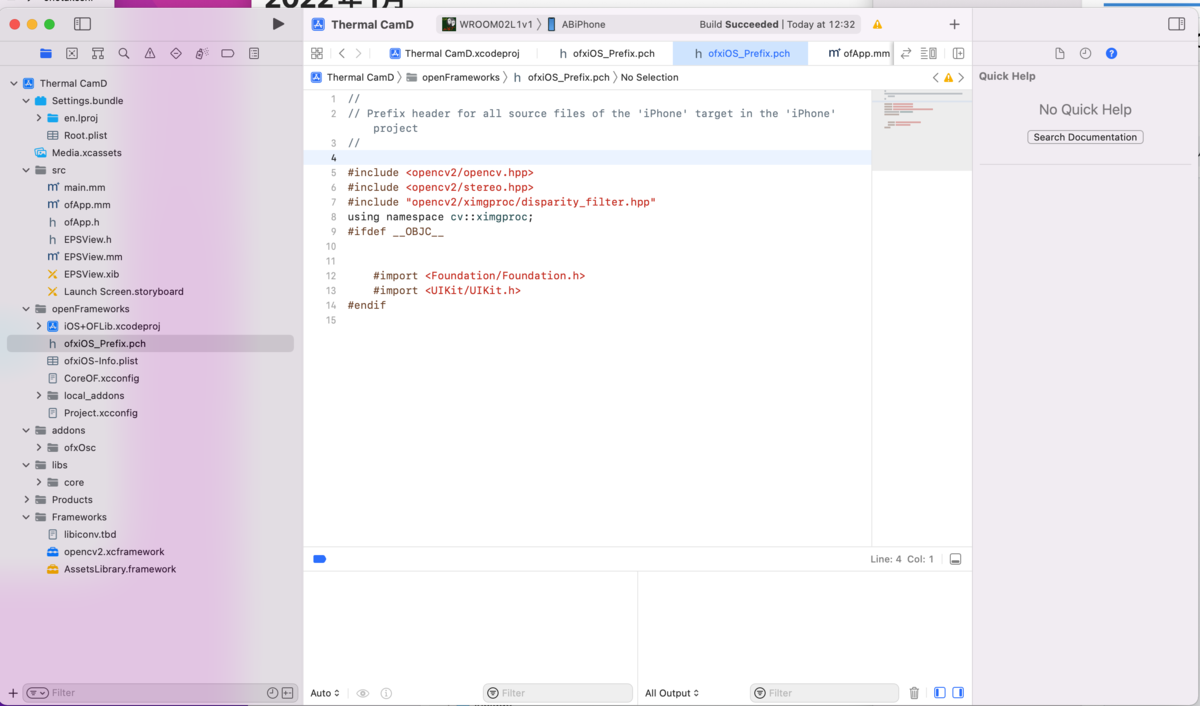
3.ofApp.cppにヘッダーファイルを指定する
以下のWebCameraを使った例のofApp.cppを参照して下さい。ここではOpenCVのヘッダーも入れています。
#include "ofApp.h"
#include "opencv2/core/utility.hpp "
//using namespace std ;
//using namespace cv ;
#include "src1/../include/yolo_v2_class.hpp" // imported functions from DLL
4.bashrc に以下の1行を追加
多分これでコンパイルが通るはずですが、yolo_v2class.hppが無いという様なエラーが出た場合は、.bashrc に LD_LIBRARY_PATHにyolo_v2class.hpp の入っているディレクトリを追加して下さい。
LD_LIBRARY_PATH=/home/????/darknet/include:$(LD_LIBRARY_PATH}
5.必要ファイルを所定のフォルダにコピーする。
OFで動いたYOLOのweightsサンプルデータは以下の3種類です。一応テスト用にダウンロードしてbinフォルダにコピーします。
https://pjreddie.com/media/files/yolov3-tiny.weights
https://pjreddie.com/media/files/yolov2.weights
https://pjreddie.com/media/files/yolov2-tiny.weights
さらに以下のファイルをdarknet/cfgから
yolov3-tiny.cfg
yolov2.cfg
yolov2-tiny.cfg
darknet/dataから以下のファイルをコピーします
coco.names
また、テスト用にbin/dataの中にフォントファイルcooperBlack.ttfをコピーして下さい。
cooperBlack.ttfは、of/examples/graphics/fontShapesExample/bin/dataに入っています。
余計なファイルも入っていますが、binフォルダの中はこんな感じになります。
DarknetをOFからそっくりそのまま使うので、認識スピードがDarknet本体より遅くなることがありません。以下は最も単純なWebCameraを使った画像認識の例です。これを発展させれば音声や画像、GPIOを含めた様々な応用ソフトが作れることになります。ビデオデータをmapに変換している部分もありますし、何より画像認識部分はOFで簡単に書けるマルチスレッドを利用してます。カメラの表示スピードは殆ど落ちないし、2つの認識スレッドを空きを見ながら処理してるので、条件が良ければ標準のものよりスピードがかなり上がります。(v2とv3に関してはtiny版が5fps位上がるようだ。なぜか標準版は変わりなし)
以下src/ofApp.h
#pragma once
#include "ofMain.h"
class public
public :
void
void
void
void int
void int
void int int
void int int int
void int int int
void int int int
void int int
void int int
void int int
void
void
ofVideoGrabber video;
ofImage img;
};
以下src/main.h
#include "ofMain.h"
#include "ofApp.h"
//========================================================================
int
usleep( 2000000 ); //YOLOがGPUの競合で止まるのを防ぐため2秒のDELAYを設ける
ofSetupOpenGL( 1024 , 768 , OF_WINDOW); // <-------- setup the GL context
// this kicks off the running of my app
// can be OF_WINDOW or OF_FULLSCREEN
// pass in width and height too:
ofRunApp( new
}
以下ofApp.cpp Xcodeからそのままコピーしたのでインデントがおかしいですがご勘弁。OFでは実質update()とdraw()を繰り返しているだけですから、AIを使うと言っても下記のようにこの部分のソース自体は非常に簡潔になります。
#include "ofApp.h"
#include "opencv2/core/utility.hpp"
//using namespace std;
//using namespace cv;
#include "src1/../include/yolo_v2_class.hpp" // imported functions from DLL
//std::string names_file = "coco.names"; //yolov2を動かす場合
//std::string cfg_file = "yolov2.cfg";
//std::string weights_file = "yolov2.weights";
std::string names_file = "coco.names" ; //yolov3-tinyを動かす場合
std::string cfg_file = "yolov3-tiny.cfg" ;
std::string weights_file = "yolov3-tiny.weights" ;
//std::string names_file = "coco.names"; //yolov2-tinyを動かす場合
//std::string cfg_file = "yolov2-tiny.cfg";
//std::string weights_file = "yolov2-tiny.weights";
float const thresh = 0.20 ; //この数値を変えることで認識の閾値を調整する
cv::Mat mat;
ofTrueTypeFont cop20,cop50;
Detector detector(cfg_file, weights_file);//yoloの初期設定
std::vector<bbox_t> result_vec; //認識した結果のバウンディングボックスの座標
float ttt,ttt1; //Time測定で使用
//以下オブジェクト(クラス)名称を読み込むための関数
std::vector<std::string> objects_names_from_file(std::string const
std::ifstream file(filename);
std::vector<std::string> file_lines;
if return
for
std::cout << ;
file.close();
return
}
std::vector<std::string> obj_names; //オブジェクト名称の配列
//以下認識結果のバウンディングボックス座標を元にバウンディングボックスを表示する関数
//画像の中の認識した物体名、座標、大きさや数がわかるので様々な応用が可能
void const const
for auto
ofNoFill();
ofSetLineWidth(2 );
//Color Set!!
int const 6 ][3 ] = { { 1 ,0 ,1 },{ 0 ,0 ,1 },{ 0 ,1 ,1 },{ 0 ,1 ,0 },{ 1 ,1 ,0 },{ 1 ,0 ,0 } };
int const 123457 % 6 ;
int const 150 + (i.obj_id * 123457 ) % 100 ;
ofSetColor(colors[offset][0 ]*color_scale, colors[offset][1 ]*color_scale, colors[offset][2 ]*color_scale);
ofDrawRectRounded(i.x,i.y,i.w,i.h,5 );
string ss;
ss=" " + obj_names[i.obj_id]+" " +ofToString(i.prob*100 ,1 );
ofSetColor(255 );
cop20.drawString(ss, i.x,i.y+15 );
}
}
//--------------------------------------------------------------
// DetectNet部分をマルチスレッドにする。
class public
public :
void
ttt=ofGetElapsedTimef();
//ok=false;
cv::Mat imgx;
cv::cvtColor(mat, imgx, cv::COLOR_RGB2BGR);//OpenCV画像用Mat配列を認識用にRGBからBGRに変換
ok=false
result_vec = detector.detect(imgx,thresh, false ); //一番肝心な認識関数バウンディングボックスの座標列をresult_vecに格納
ok=true
ttt1=1.0f /(ofGetElapsedTimef()-ttt); //以下FPS表示
std::stringstream stm;
stm<<"Framerate : " << ofToString(ofGetFrameRate(),2 )<<" FPS YOLO : " <<ofToString(ttt1,2 )<<" FPS" ;
ofSetWindowTitle(stm.str());
stopThread();
}
bool
};
matmat Found_X,Found_Y;//2つのタスクを宣言
//--------------------------------------------------------------
void
obj_names = objects_names_from_file(names_file);//オブジェクト名称をファイルから読み込む
cop20.load("cooperBlack.ttf" , 10 , true , true , true ); //字体の初期設定
cop50.load("cooperBlack.ttf" , 20 , true , true , true ); //字体の初期設定
video.setDeviceID( 0 );//WebCamera ディバイス番号 通常は0
video.setup(960 ,720 ,OF_PIXELS_RGBA);//WebCameraの初期設定
Found_X.ok= true ; //マルチスレッドの前処理
Found_Y.ok= true ; //マルチスレッドの前処理
}
//--------------------------------------------------------------
void
video.update();
if true
//ビデオフレームが更新されたら2つのタスクの空いている方でAI認識させる
if
mat=cv::Mat(video.getHeight(),video.getWidth(),CV_8UC3,video.getPixels().getData());//認識用の画像をOpencv Mat形式に変更
Found_X.stopThread();Found_X.startThread();;
}
else if
mat=cv::Mat(video.getHeight(),video.getWidth(),CV_8UC3,video.getPixels().getData());
Found_Y.stopThread();Found_Y.startThread();
}
}
}
//--------------------------------------------------------------
void
ofSetColor(255 );
video.draw( 0 , 0 );//WebCamera画像を表示する
Found_X.lock();//ここで他のタスクをロックしないとプログラムがダウンする
Found_Y.lock();
show_console_result(result_vec, obj_names);//バウンディングボックスを描画する
Found_X.unlock();
Found_Y.unlock();
}
//--------------------------------------------------------------
void int
}
//--------------------------------------------------------------
void int
}
//--------------------------------------------------------------
void int int
}
//--------------------------------------------------------------
void int int int
}
//--------------------------------------------------------------
void int int int
}
//--------------------------------------------------------------
void int int int
}
//--------------------------------------------------------------
void int int
}
//--------------------------------------------------------------
void int int
}
//--------------------------------------------------------------
void int int
}
//--------------------------------------------------------------
void
}
//--------------------------------------------------------------
void
}
OFでYOLOを使う場合の条件
yolov3はメモリが不足して使えない。
yolov2は設定の変更でなんとか動くが、途中で止まる場合は何回か再実行を試みる。
yolov2.cfg の最初の方のパラメーターを4箇所変更してみて下さい
batch=1
subdivisions=64
width=320
height=320
※width,heightは32の倍数。nanoでは416が限度
yolo v3 tinyは応用できるが現行のサンプルデータはなんか変。プログラム上のバグがある模様。yolov2 tinyより認識率がかなり落ちるようだが、データ数か学習が失敗してる可能性もある。(私の学習させたジャンケンではそんなことはなかった)
yolov2 tiny が良いみたい。ただし誤認識が多い
ということを考慮するとでtinyを使った場合、nanoで問題なくアプリが作れます。それもyolov2-tinyが良い様です。
これ以上を望むならTX2やXavierということになりますが、nanoでも殆ど問題ないことが分かりますでしょうか。
以下画像は、このアプリを使って実際に実行させた結果です。
yolov2を使った画像認識 yolov2.cfgは上記設定。treash=0.2 かなり良いが遅い->5fps程度。ただし動画は60fps。本来のカメラ性能は30fpsなので、まだまだCPU処理部分に余裕がある=凝ったアプリが作れる
yolov3-tinyを使った画像認識 cfg内容は変更なし。treash=0.1 18~25fpsくらいで認識するがバウンディングボックスの範囲が実際より小さく多重認識がある。前にオリジナルデーターで学習させた時の経験上、使ったcfgファイルが今回のサンプルデータと 合っていない可能性がある。(自分で学習させた時は全く問題なかった)
yolov2-tinyを使った画像認識 cfg内容は変更なし。treash=0.5 この数値以下にするとかなり小さい対象物も認識するが誤認識も多くなる。これも18~25fpsくらいで認識する。
最後に外付けSSDに開発環境を移行する。
SDカードでも単独開発できますが、寿命や信頼性の問題、さらにリードライトスピードが遅いので、開発には向きません。SSDにそっくりそのまま移行した方が、OSのレスポンスも早くなります。
以下「サメおじさんのブログ」を参考にして、全く問題なく全ての環境がSSDに移行できました。
Jetson Nano - Run on USB Drive - JetsonHacks
SDカードに最終環境が残っているので、外部で使う時などは、またSD環境に戻してSSD無しで使えることが利点です。SDブートに戻すには、
SD側の/boot/extlinux/extlinux.confの中身
APPEND ${cbootargs} rootfstype=ext4 root=/dev/sda1 rw rootwait
の sda1をmmcblk0p1に変更
SSDブートの場合はsda1に変更します。ただしスペルを間違うと2度と起動しなくなるので注意が必要です。(その場合でも他のUbuntuマシンを使って修正は可能)
この環境ではブート時に一旦SDを見に行ってからSSDにOSを移行する設定なので、SDは取り付けたままにします。SSDを外した場合起動しなくなるので注意が必要。再度SSDを接続してリブートすれば問題なく動きます。
Jetsonフォーラムで、M.2スロットに変換ボードを接続すればSSDが接続できるかも....とメーカー側の投稿があり、試してみたら全くディスクとして認識されませんでした。 (ダメ元でもう少しトライしてみますけど)
アーくやしい!!
この頃気候のせいか体調があまり芳しくなく、頭がボーとしていて文章がまとまりません。分かりにくいところはコメントください。
ではでは。





 アルミフレームとセンターキャップのアルミは、金属磨きで何回も擦る。別にペーパーをかけなくともあっという間に新品のようになった。
アルミフレームとセンターキャップのアルミは、金属磨きで何回も擦る。別にペーパーをかけなくともあっという間に新品のようになった。 ターミナルもケーブルも取り替えたところで私の耳には変わりないと思えるので、現状のまま。取り付けビスも多少汚れを取って。リード線の先端は少し切ってハンダを染み込ませた。
ターミナルもケーブルも取り替えたところで私の耳には変わりないと思えるので、現状のまま。取り付けビスも多少汚れを取って。リード線の先端は少し切ってハンダを染み込ませた。